随着互联网的快速发展,诸如云计算、微服务、开源工具和基于容器交付等技术,使得应用程序在日益复杂的环境中更加分散,因此,追踪请求在分布式系统中链路变得至关重要。
那么,什么是分布式追踪?它又是如何工作的呢?本文我们将深入进行分析。

分布式追踪(Distributed Tracing)是一种用于监控和诊断分布式应用程序性能的技术。在分布式系统中,服务通常会被拆分成多个微服务,它们可能运行在不同的服务器或容器中,并通过网络相互通信。分布式追踪通过跟踪和记录请求在整个系统中的传播路径和性能数据,帮助开发人员和运维团队分析服务之间的调用关系、排查性能瓶颈和故障。
通常,分布式追踪系统会生成唯一标识每个请求的 TraceId,并记录每个服务处理请求的时间、耗时、调用链路等信息。这些数据可以用于生成可视化的调用图,帮助开发者理解系统内部各个服务之间的依赖关系和性能状况。如下图为一个简要的分布式系统追踪网:

在单体应用程序时代,掌握系统中发生的情况相对简单,然而,分布式系统通常由多个独立的微服务组成,这些服务之间通过网络进行通信,服务的数量和相互依赖关系的增加使得问题的定位和解决变得更加复杂,这些复杂性给内部协作带来了巨大的挑战,同时也大大增加了问题排查的难度和成本。
因此,急需一种手段,能够在分布式系统中进行全链路追踪,所以分布式追踪就诞生了。
分布式追踪对于监视、调试和优化分布式软件架构(如微服务)至关重要,尤其是在动态微服务架构中,它通过收集和分析与请求触及的每个服务的每次交互的数据来追踪单个请求。
分布式追踪还可以帮助团队更快地了解每个微服务的执行情况,这种理解有助于他们快速解决问题,提高客户满意度,确保稳定的收入,并为团队保留创新时间。通过这种方式,企业可以充分利用现代应用程序环境提供的优势,同时最大限度地减少其固有的复杂性也可能带来的挑战。
分布式追踪系统主要有以下几种类型:
(1) 基于采样的追踪
采样方式又可以细分三种,其详情如下:
(2) 基于调用链的追踪
基于调用链也可以分为两种方式,其详情如下:
(3) 基于日志的追踪
(4) 基于事件的追踪
分布式追踪的工作原理涉及多个组件和步骤,我们通过以下 7个主要流程进行分析:
(1) 唯一标识
在分布式追踪中,一般都会存在两个重要的唯一标识:Trace ID 和 Span ID。
(2) 追踪上下文传递
当一个请求从一个服务传递到另一个服务时,Trace ID 和 Span ID 会放置在请求头中传递,以确保追踪上下文在整个调用链中保持一致。
例如,在 HTTP请求中,追踪信息可以通过特定的 HTTP头(如 X-B3-TraceId, X-B3-SpanId 等)传递。
(3) 生成和记录Span
每个服务在接收到请求时,会生成一个 Span,记录该请求的开始时间、结束时间、处理时长、调用的下游服务等信息。Span 还可以包含标签(tags)和日志(logs),用于记录额外的上下文信息,如请求参数、错误信息等。
(4) 数据收集和传输
每个服务会将生成的 Span 数据发送到集中式追踪收集器(Collector),可以通过多种方式传输数据,如 HTTP、gRPC 等。数据收集器接收到 Span 数据后,会对其进行处理、存储和聚合。
(5) 数据存储
收集到的追踪数据通常会存储在分布式存储系统中,如 Elasticsearch、Cassandra、Jaeger内置存储等,以支持高效的查询和分析。
(66) 数据分析和可视化
通过追踪系统的用户界面或可视化工具,用户可以查询和分析追踪数据,生成调用图、时间线图等,直观地展示请求的路径和各个服务的性能。常见的可视化工具包括 Jaeger UI、Zipkin UI 等,它们提供了丰富的过滤、搜索和分析功能。
(7) 集成和扩展
分布式追踪系统通常提供多种 SDK 和集成工具,支持在不同的编程语言和框架中嵌入追踪代码。还可以与其他监控和日志系统集成,形成统一的可观测性平台,如与 Prometheus、Grafana、ELK 等工具集成。
通过上述步骤,分布式追踪系统能够全面地跟踪和分析请求在分布式系统中的传播路径和性能,帮助开发者和运维人员深入理解系统的行为和性能,以下为一张简要的追踪原理图:
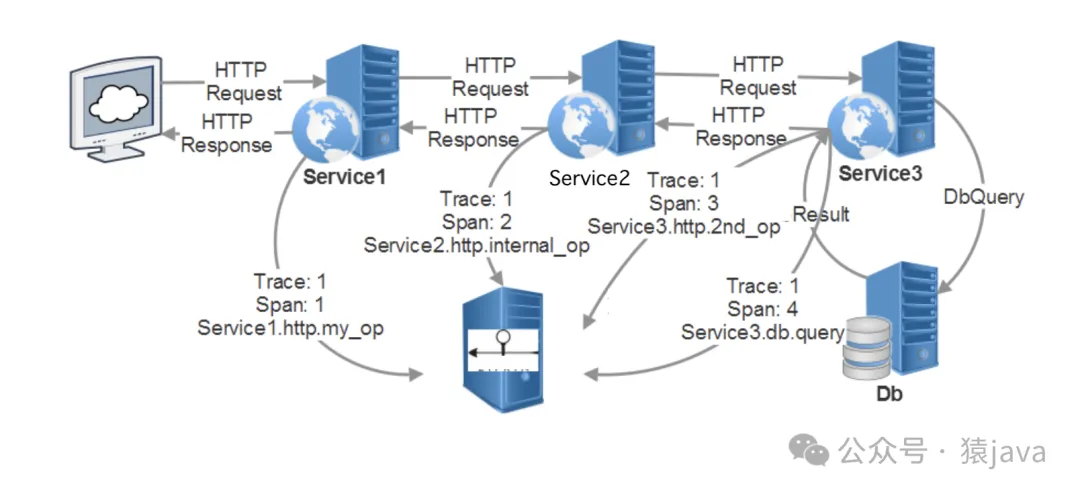
尽管分布式追踪为企业提供了许多优势,但在实现和维护过程中面临一些挑战,包括技术复杂性、性能开销、数据管理等方面,以下是一些主要的挑战:
(1) 性能开销
追踪数据的收集、传输和存储会带来额外的性能开销,特别是在高并发和大规模系统中,这种开销可能会影响系统的整体性能。
(2) 数据量大
分布式系统中的每个请求可能涉及多个服务,每个服务都会生成追踪数据,导致数据量非常庞大。有效地存储、管理和查询这些数据是一项重大挑战。
(3) 全链路追踪的难度
确保追踪上下文在整个调用链中传递一致性是一个复杂的问题,尤其是在跨语言、跨平台和跨团队的系统中。任何一个环节出现问题,都会导致追踪数据的不完整或不准确。
(4) 采样策略的选择
在高流量系统中,不可能对每个请求都进行追踪,需要选择合适的采样策略来平衡追踪数据的代表性和系统的性能开销。制定和调整采样策略需要对系统有深入的了解。
(5) 可视化和分析
大量的追踪数据需要有效的可视化和分析工具来帮助开发者和运维人员理解系统的行为和性能。设计和实现高效的可视化工具是一个挑战。
(6) 数据一致性和可靠性
确保追踪数据的准确性和一致性,避免数据丢失或错误,尤其是在系统发生故障或网络不稳定的情况下。
(7) 跨团队协作
实现和维护分布式追踪需要开发、运维、安全等多个团队的协作。不同团队之间的沟通和协调是一个重要的挑战。
(8) 隐私和安全
追踪数据可能包含敏感信息,确保数据的隐私和安全是必须的。需要采取适当的措施来保护数据不被未经授权的访问和泄露。
(9) 适应多样化技术栈
现代分布式系统通常使用多种编程语言、框架和平台。需要支持多样化技术栈的追踪工具和标准,以确保在不同环境中的一致性和兼容性。
(10) 成本管理
存储和处理大量追踪数据可能带来高昂的成本。需要有效的成本管理策略,如数据压缩、归档和自动删除过期数据等。通过识别和应对这些挑战,可以更好地实现和维护分布式追踪系统,从而充分发挥其在性能监控和故障诊断中的优势。
对于分布式追踪工具,市面上主要有三类:自研,开源,商业版。以下是一些常用的分布式追踪工具:
(1) Zipkin
Zipkin是 Twitter基于 Java语言开发的开源分布式追踪系统,支持多种语言和框架,易于集成。Zipkin提供简单的用户界面,用于查看和分析追踪数据,支持多种存储后端,如 MySQL、Elasticsearch等。
(2) SkyWalking
SkyWalking 是一个开源的应用性能监控和分布式追踪系统,由国内 Apache基金会成员吴晟创立。它支持多种语言,包括Java、C#、Go等,能够监控和追踪分布式系统中的调用链路。
(3) Pinpoint
Pinpoint是由韩国 Naver开源的分布式追踪系统,专注于 Java和 PHP应用的监控和追踪,它能够详细记录服务的调用链路和性能数据,帮助开发者优化系统性能。
Pinpoint 提供直观的界面,方便用户分析和定位问题,支持自定义插件,方便集成到不同的系统中。适用于需要详细调用链路和性能数据的 Java和 PHP应用。
(4) CAT
CAT(Central Application Tracking)是由国内知名互联网公司美团点评开源的分布式追踪和监控系统,专注于应用性能监控和故障排查,它能够实时收集和分析系统中的调用链路和性能数据。
CAT能够实时收集和分析系统中的调用链路和性能数据,支持Java、C++、Node.js等多种语言,提供强大的可视化界面,帮助用户深入分析系统性能。适用于需要实时监控和故障排查的分布式系统。
(5) 其他
另外还有一些国外比较流行(可能在国内不常用)的追踪工具,比如:Jaeger,OpenTelemetry,AWS X-Ray,Azure Application Insights,Google Cloud Trace,Elastic APM等。
本文分析了什么是分布式追踪?为什么需要分布式追踪以及分布式追踪如何工作的,其实,分布式追踪就是让错综复杂的分布式系统调用变得透明化和可视化。
有了分布式追踪,我们才能更好的掌握服务之间的调用关系,及时监控服务器的各项指标,当出现故障时可以快死定位,因此,分布式追踪是分布式系统中不可或缺的一项技术,在国内的中大型互联网公司,都有一个专门的部门在维护着这样的服务,足以可见其重要性。
本文链接:http://www.28at.com/showinfo-26-99903-0.html分布式链路追踪,一文帮你掌握它!
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。邮件:2376512515@qq.com
上一篇: 五分钟挑战:Python while 循环的七种高效玩法!
下一篇: C# 验证PDF签名有效性的技术探讨
Copyright © 2016-2023 天津谷骐科技有限公司 版权所有 sitemap.xml
违法及侵权请联系:2376512515@qq.com 津ICP备18001702号
 津公网安备 12010102000574号
津公网安备 12010102000574号
