什么是字符集?什么是编码?什么是解码?它们之间有什么关系?ASCII、Unicode、UTF-8、ISO-8859-1、GB2312,这些在计算中常见的名词,它们代表的真正含义是什么?这篇文章帮你讲透!

字符集(Character Set)是字符的一个集合,包含字母、数字、标点符号、控制字符、中文以及其他符号。常见的字符集包括:
编码(Encoding)是将字符集中的字符转换为计算机可以处理的二进制数据的规则或方案。不同的编码方式会使用不同的二进制模式来表示同一个字符。常见的编码方式包括:
解码(Decoding)是将编码后的数据还原为其原始格式的过程,解码通常是编码的逆过程。
通过上面的描述可以知道:GB2312,GBK,GB18030 它即包含一套字符集,也包含了对应的一套编解码。
计算机起源于美国,计算机内部使用的是二进制(0/1),而美国的通用的语言是英文,于是,为了规范英语字符与二进制位之间的关系,在上个世纪60年代,美国制定了一套字符编码,这就是一直沿用至今的 ASCII 码。
在英语里,除了 26个英文字母的大小写,再加上一些通用的符号,总共 128个字符(包括 32个不能打印的控制符号),因此,ASCII码也定义了与之对应的 128个编码,比如,字母 A的 ASCII码是十进制 65(二进制:01000001)。
对于 128=2⁷ 个字符,只需要一个字节就能存储(1byte = 8bit),而且只需要占用了一个字节的后面7 位,因此,ASCII码规定二进制的最前面的一位统一为 0。如下为一张 ASCII码表:
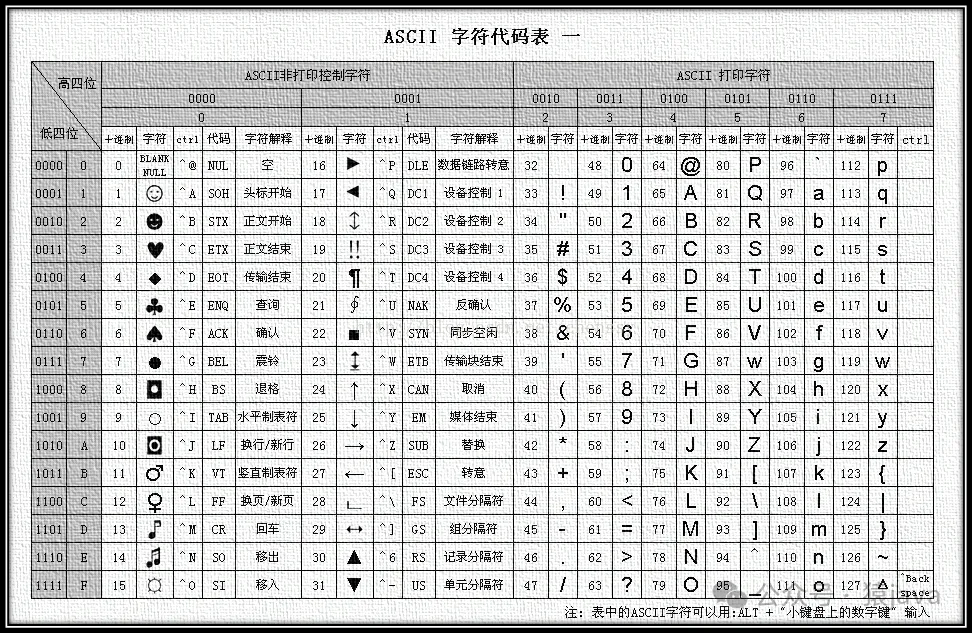
所以,ASCII码是为了英语使用者能够把常用的 128个字符存储在计算机中而设置的一套规则。
ASCII码的设计很优秀,但对于中文使用者,怎么能接受计算机存储不了中文的现实?于是,聪明的中国人在 1980年发布了一套适用自己的新编准:GB2312。
GB2312 是中华人民共和国国家标准《信息交换用汉字编码字符集 基本集》的简称,全称为 GB 2312-1980。该标准定义了用于简体中文字符和一些其他字符的编码方法,而且兼容 ASCII,广泛应用于中文信息处理系统中。
GB2312是一个双字节编码字符集,即 GB2312中的所有字符都使用两个字节进行编码和存储,具体编码结构如下:
GB2312 总共有 7445个字符,主要包括 6763个汉字和 682个非汉字字符(如 ASCII、拉丁字母、希腊字母、日文假名、符号等)。具体分为以下两个部分:
GB2312 编码表可以通过下面这两个特定的公式计算得到:
以“你好” 为例来演示:
“你”在 GB2312编码表中位于第 36区第 67位:
高字节:0xA1 + 36 - 1 = 0xC4低字节:0xA1 + 67 - 1 = 0xE3因此,"你"的 GB2312编码为 0xC4E3,和 GB2312编码表中的值可以对应上。“好”在 GB2312编码表中位于第 26区第 35位:
高字节:0xA1 + 26 - 1 = 0xBA低字节:0xA1 + 35 - 1 = 0xC3因此,"好"的 GB2312编码是 0xBAC3,和 GB2312编码表中的值可以对应上。随着互联网的快速发展,GB2312编码表中定义的字符已经不够用了,因此,GB2312的扩展版 GBK编码表诞生了。
GBK是“国标扩展字符集”前 3个汉字拼音首字母的缩写,全称是《汉字内码扩展规范》(Chinese Internal Code Extension, GBK)。GBK字符集是 1993年发布的,它是对 GB2312的扩展。
GBK是一个双字节编码字符集,每个字符由一个或两个字节表示。其编码结构如下:
① GBK扩展了 GB2312的编码范围,使其支持更多字符
② 单字节部分(与 ASCII兼容):0x00 - 0x7F
③双字节部分:
GB18030 是国家标准化委员会(SAC)发布的字符编码标准,是一种用于汉字、汉语拼音、注音符号和汉字部首等文字的字符集和编码方案,它是继 GB2312和 GBK 后更强筋的版本。
GB18030的特点包括:
ISO-8859-1,全称为”ISO/IEC 8859-1”,是国际标准化组织(ISO)和国际电工委员会(IEC)发布的字符编码标准之一,也被称为 Latin-1或 Western European (ISO)。它是 ISO-8859系列中的第一个字符编码标准,旨在支持西欧地区的主要语言,如英语、法语、德语、西班牙语等。
ISO-8859-1的特点包括:
ISO-8859-1的一些限制:
总的来说,ISO-8859-1是一个针对西欧语言的基本字符编码标准,虽然在全球范围内的使用逐渐减少,但在某些特定的场景和遗留系统中仍然可能会遇到。
上面介绍的字符集,要么是为英语或者西欧使用者设计的,要么是兼容汉字但对其他语言不友好,因此,有没有一种全球通用并且包含全球所有通用的字符呢?
于是,Unicode字符集诞生了!
Unicode,正如它的中文意思“统一码”一样,它包含了世界上所有的通用符号(超过 110多万个符号),而且给每个符号赋予一个独一无二的编码,通常表示为:U+后跟一个十六进制数,例如,U+56fd 表示汉字的“国”,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的字母 A等。
Unicode尽管包含了全球所有通用的字符,但它只是统一了所有的字符集,也就是说它只规定了符号的二进制代码格式,却没有规定这个二进制代码应该如何存储(编解码)。
比如,Unicode 包含的这些字符集中,有的 1个字节能存储,有的 2个字节能存储,有的需要 4个字节才能存储,因此,对于一个 Unicode字符,计算机如何知道需要采用几个字节来存储?基于此局面,急需一套统一的编码方式。
对于 Unicode字符集,通常有 UTF-8,UTF-16,UTF-32等编码方式。
UTF,Unicode Transformation Format(Unicode 转换格式),而 UTF-8是目前互联网上使用最广的一种 Unicode实现方式,因此,本文重点分析 UTF-8。
UTF-8 是一种变长的编码方式,使用 1~4个字节来表示不同的 Unicode字符:
UTF-8 编码的字节结构如下:
1字节: 0xxxxxxx2字节: 110xxxxx 10xxxxxx3字节: 1110xxxx 10xxxxxx 10xxxxxx4字节: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx通过上述字节结构,可以总结两个规律:
(1) 字符 ‘A’ (U+0041)
分析:字符’A’的 Unicode是 U+0041,位于 U+0000 到 U+007F之间,因此,一个字节就可以表示,因此,二进制为:01000001,转成十六进制为:0x41
(2) 字符 ‘€’ (U+20AC)
分析:字符 ‘€’的 Unicode是 U+20AC,位于 U+0800 到 U+FFFF之间,因此,需要用 3个字节表示,即1110xxxx 10xxxxxx 10xxxxxx,将“20AC”中的每个字符直接转换成二进制为:0010 0000 1010 1100,然后将它从低位往高位(从右到左)依次替换x,如下图:
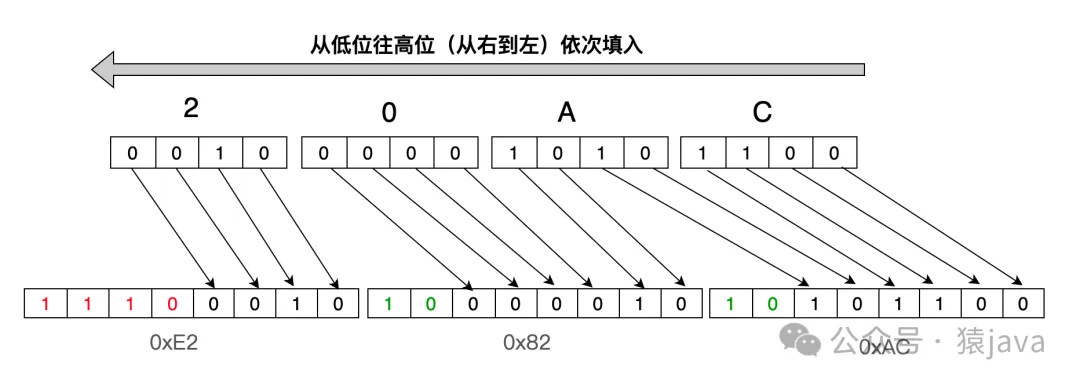
这样得出字符 ‘€’ (U+20AC)用 UTF-8编码的二进制为:11100010 10000010 10101100,转换成十六进制为:0xE2 0x82 0xAC
使用过 MySQL数据库的小伙伴对 utf8mb4肯定不陌生,它是 MySQL数据库中的一种字符集,具体来说是 UTF-8的一个变种,能够支持所有的 Unicode字符,包括那些需要 4个字节表示的字符(例如某些 emoji表情符号和一些罕见的汉字)。
在 MySQL中,utf8字符集最多支持 3个字节的字符,因此,它不能存储所有的 Unicode字符,而 utf8mb4字符集支持 4个字节的字符,能够存储所有的 Unicode字符。
因此,在一些涉及聊天业务的场景,utf8mb4字符集经常被使用,主要是用于存储 emoji表情,比如:
本文链接:http://www.28at.com/showinfo-26-91516-0.htmlASCII、Unicode、UTF-8、utf8mb4,有啥区别?
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。邮件:2376512515@qq.com
上一篇: 我们一起聊聊C# 开启线程的四种方式
Copyright © 2016-2023 天津谷骐科技有限公司 版权所有 sitemap.xml
违法及侵权请联系:2376512515@qq.com 津ICP备18001702号
 津公网安备 12010102000574号
津公网安备 12010102000574号
